What You’ll Need
To get started, you’ll need the following:
- Python installed on your computer.
- A code editor (e.g., Visual Studio Code).
- A stable internet connection.
- A little patience and enthusiasm!
Setting Up Your Environment
To ensure a smooth web scraping experience, let’s set up your Python environment using Visual Studio Code (VSCode), a popular code editor. This section will guide you through installing the required Python libraries and configuring your VSCode workspace.
Step 1: Install Visual Studio Code
If you haven’t already, download and install Visual Studio Code from the official website: https://code.visualstudio.com/ץ Download the default version that fits your OS.
Step 2: Install the Python Extension
To work with Python in VSCode, you’ll need to install the official Python extension. Follow these steps:
- Open Visual Studio Code.
- Click on the Extensions icon in the Activity Bar on the side of the window.

- Search for “Python” in the Extensions search bar.
- Find the official Python extension by Microsoft, and click the “Install” button.
Step 3: Create a New Project Folder
Create a new folder for your Zillow scraper project. You can do this directly in VSCode:
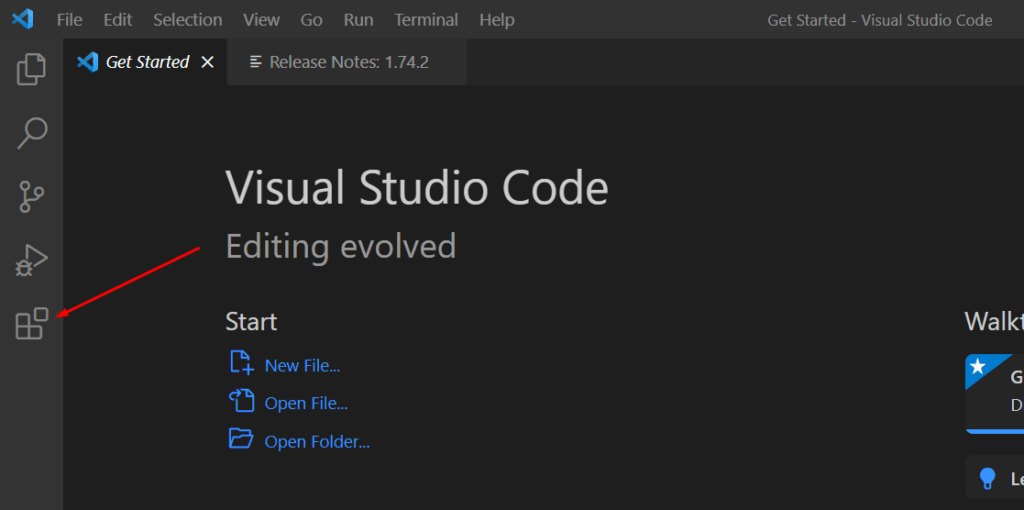
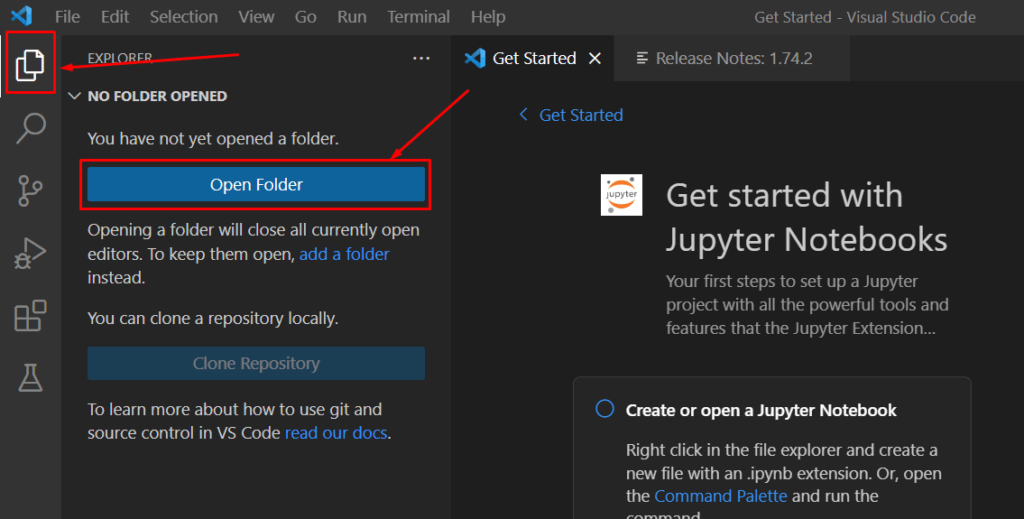
- Click on the Explorer icon in the Activity Bar.
- Click on “Open Folder” and create a new folder for your project.

- Click “Select Folder” to open the folder in VSCode.
Step 4: Create a Python File
In your project folder, create a new Python file:
- Right-click on the empty space in the Explorer.
- Click on “New File” and name it “
zillow_scraper.py“.
Step 5: Install the Required Libraries
You’ll need to install a couple of libraries to make the scraping process easier:
- Requests: A library for making HTTP requests.
- BeautifulSoup: A library for parsing HTML and XML documents.
To install these libraries, open the integrated terminal in VSCode:
- Click on “Terminal” in the top menu.
- Select “New Terminal”.
Now, type the following command in the terminal:
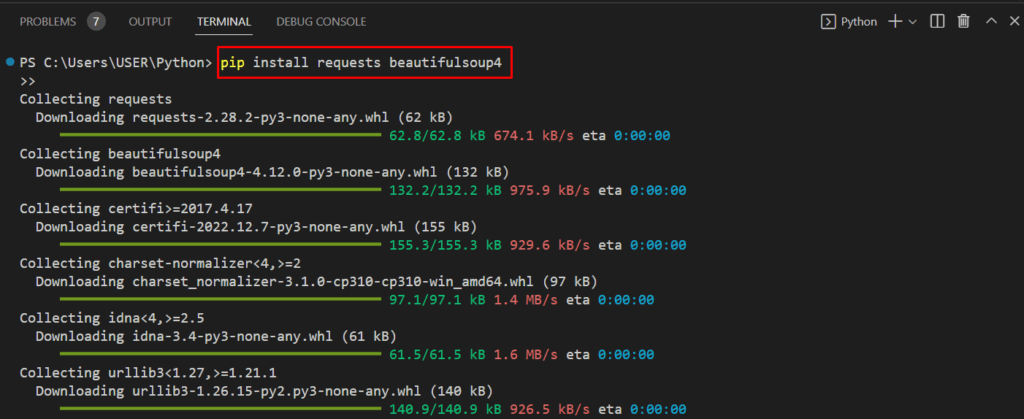
You’re all set! Your Python environment is ready for web scraping in Visual Studio Code. You can now proceed with writing the code to scrape Zillow property listings as explained in the previous sections of this guide.
The Basics of Web Scraping
Web scraping is the process of extracting data from websites. In our case, we’ll be extracting property data from Zillow. To do this, we’ll send an HTTP request to a Zillow URL, receive the HTML response, and parse the data we need using BeautifulSoup.
Step 1: Send an HTTP Request
Using the requests library, you can send an HTTP request to Zillow’s URL. Here’s an example:
